Corpus versions
Grac.v.17, 17a
The corpus counts 1.781 billion tokens.
The collection of Western Ukrainian press of the 1890s-1940s, the Twitter corpus, and forums have been added. The collection of online news for 2022 has been reduced.
Added a style (doc.style): ICM (Internet communication).
New markup attributes are available in version 17a: doc.mediaAdmin (political affiliation of the media), doc.ageCode (age group, for children's literature).
Grac.v.16
The corpus counts 1.875 billion tokens.
Two large collections of news downloaded from online sources have been added: news from 2000-2022 with about 600 million tokens (UberText), and news from 2022, 190 million tokens (PAWUK -- Polish Automatic Web Corpus of the Ukrainian Language, IPI PAN).
Texts from printed sources have been added, including a collection of texts from the "Vsesvit" magazine for 1923-1928, texts from diaspora magazines such as "Samostiyna Ukraina" (late 1940s - early 1950s) and "Kvituchi Berehy" (1960s-1980s), the complete works of Mykhailo Semenko, the complete works of Volodymyr Leontovych, etc.
A new module for lemmatization of texts in the old spelling (by Lesya Ukrainka), described in the paper, has been connected.
Grac v.15
The corpus counts 889 million tokens.
Grac v.14
The corpus counts 860 million tokens. New cleaning algorithms have been applied to the texts.
New tags added:
punct - a symbol that can be a punctuation mark in the Ukrainian text
symb - another symbol
unknown - an unknown word, a sequence of Ukrainian letters
unclass - other unknown sequences of non-Ukrainian letters and symbols
The lemma for unknown words in GRAC v.14 is equal to the word form (in previous versions, unknown words had an empty lemma).
Grac v.13
The corpus counts 861 million tokens.
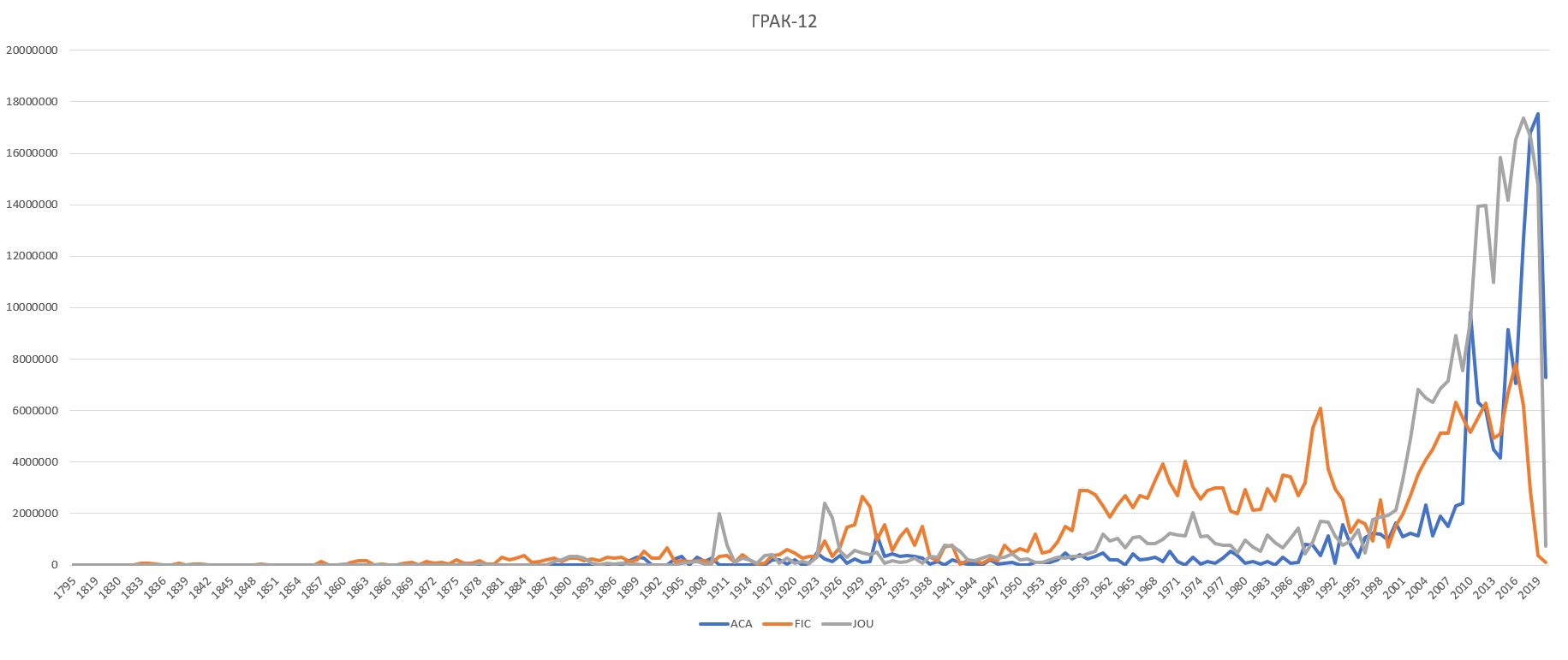
Grac v.12
The corpus counts 823 million tokens. In the last three versions, the journalism collection is updated, in particular the 20-century newspapers.
The corpus word list features now words with the od- prefix (variant of the standard vid-), now they are lemmatized and searchable.
Contents of the corpus by years:
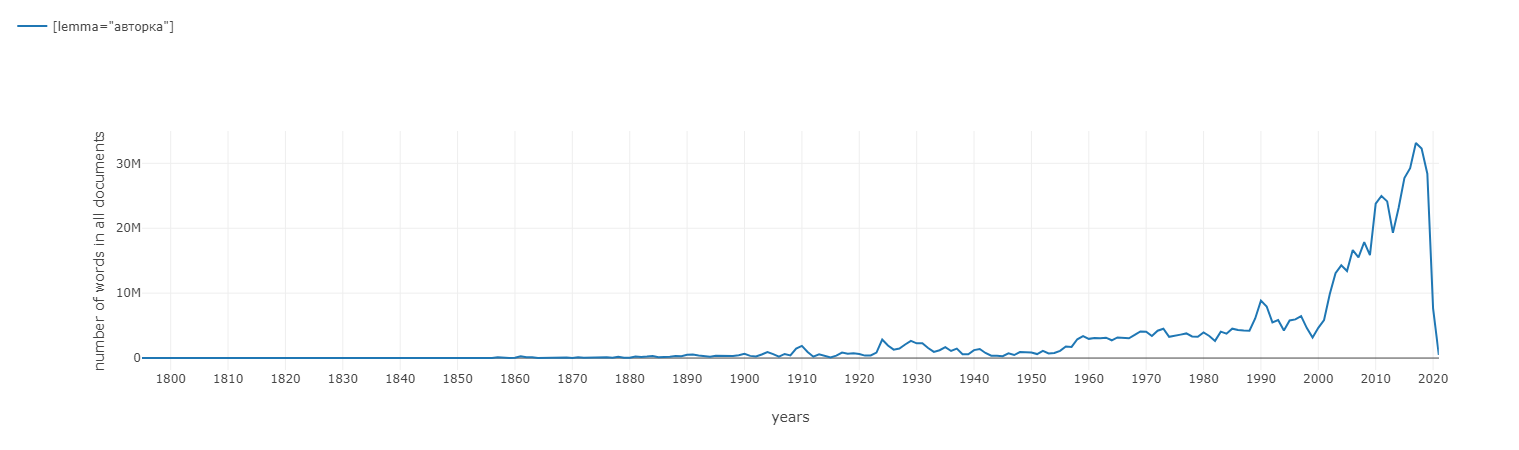 Number of tokens in academic, fiction and journalistic texts (ACA, FIC, JOU) by years:
Number of tokens in academic, fiction and journalistic texts (ACA, FIC, JOU) by years:
Grac v.9
For tagging Grac 9 we used the updated VESUM that tags marginal grammatical forms:
1) the most frequent contracted verbal forms of the third person: зна, співа...
CQL: [tag="verb.*3:short"]
2) infinitives in-ть: писать, допомагать...
CQL: [tag="verb.*inf:short"]
3) the most frequent non-contracted forms of adjectives: гарная, хорошая...
CQL: [tag="adj.*long"]
4) short adverbial comparatives: гарніш, сильніш...
CQL: [tag="adv.*short"]
5) gerunds in -ся: стріляючися, миючися...
CQL: [tag="advp.*long"]
6) the most frequent imperatives in -те: окропіте, хваліте
CQL: [tag="verb.*2:long"]
The 9th version includes the following new texts:
1) about 600K tokens of newspaper texts (1920s-1930s) mostly from the Naddnipryanshchina region from the libraria website; the magazine "Muzyka masam" (1928, 1929), about 350K tokens;
2) new diaspora texts. The whole diaspora subcorpus has doubled and counts now about 40M tokens. It includes fiction and magazines Suchasnist' (Munich, 1961-1991), Visti kombatanta (New York, Toronto, 1961-2014) - currently the issues are not divided into texts;
3) separate numbers of the magazines Ukrayins'kiy pasichnyk, Pasika, Syhnal etc. (1990s-2000s);
4) online editions Yevropeys'ka pravda (2014-2016), Firtka (2010-2020), Reporter (2014-2020), Versiyi (2013-2020), not divided into texts, and Ukrayins'kyy tyzhden' (2008-2019) divided into texts;
5) more than 300 dissertations in different fields of knowledge (2018-2019);
6) the most important works of Ukrainian linguists (different periods).
Grac v.8
The eight corpus includes the texts from the newspaper Vysokyj zamok (2001-2017) counting 53M tokens caw caw caw, the texts from the Vsesvit for 1958-1979 counting 17M tokens (including 4,8M tokens of journalism), texts from the journal Nauka i suspil'stvo (1972-1994) counting 4,2M tokens, texts from the Western Ukrainan newspapers (1945-1946) counting 0,5M tokens.
Grac v.7
The corpus includes 437M tokens. New texts: selected issues of the magazine Molode zhittya of the Plastuny (Scouts) movement (1925-1929), about 100 issues of the Vsesvit magazine (1958-1983), a collection of the Soviet newspaper articles about the Chernobyl disaster (1986-1991), a collection of modern drama, the newspaper Ukrayina moloda for 2010-2019.
Grac v.6
The sixth version is the first one to feature poetic texts.
Grac v.5
The fifth version of the corpus was updated mainly with non-fiction, including the Ukrainian Historical Journal (selected issues 1957-1990) and some other academic and journalism texts of the Soviet period as well as a collection of modern academic publications from the journals of the Ukrainian Academy of Sciences in different fields of knowledge (more than 20M tokens).
Grac v.4
Filters for selecting texts (DOC.AUTHOR, DOC.BORN etc) were added in Grac v.4.
The main rules for analyzing the Zhelekhivka texts were added. The program lemmatizes correctly examples like називати ся, цїлком, мякий, сьвіт.